For any company dealing with large quantities of information, finding an effective Intelligent Document Processing (IDP) solution is a great opportunity to improve process efficiencies, reduce costs and increase margins. However, IDP is a large bucket that encompasses very different solutions, starting from scanning handwritten content, capturing data from digital forms, as well as classifying and processing complex documents like contracts or insurance policies.
To fully leverage the benefits of intelligent document processing in your organization, you should first consider the use cases you wish to apply IDP to and determine the type of content involved.
Here are four key facts to get you started:
80% of the data produced worldwide is unstructured
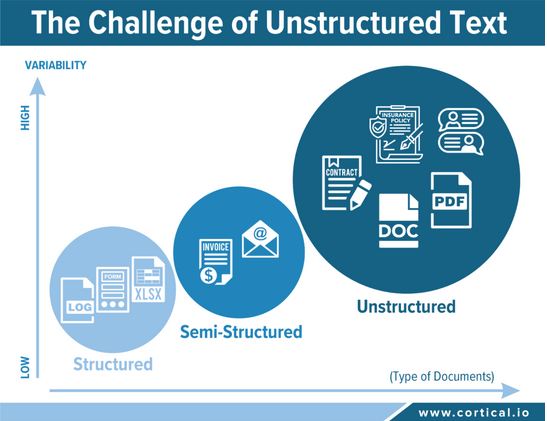
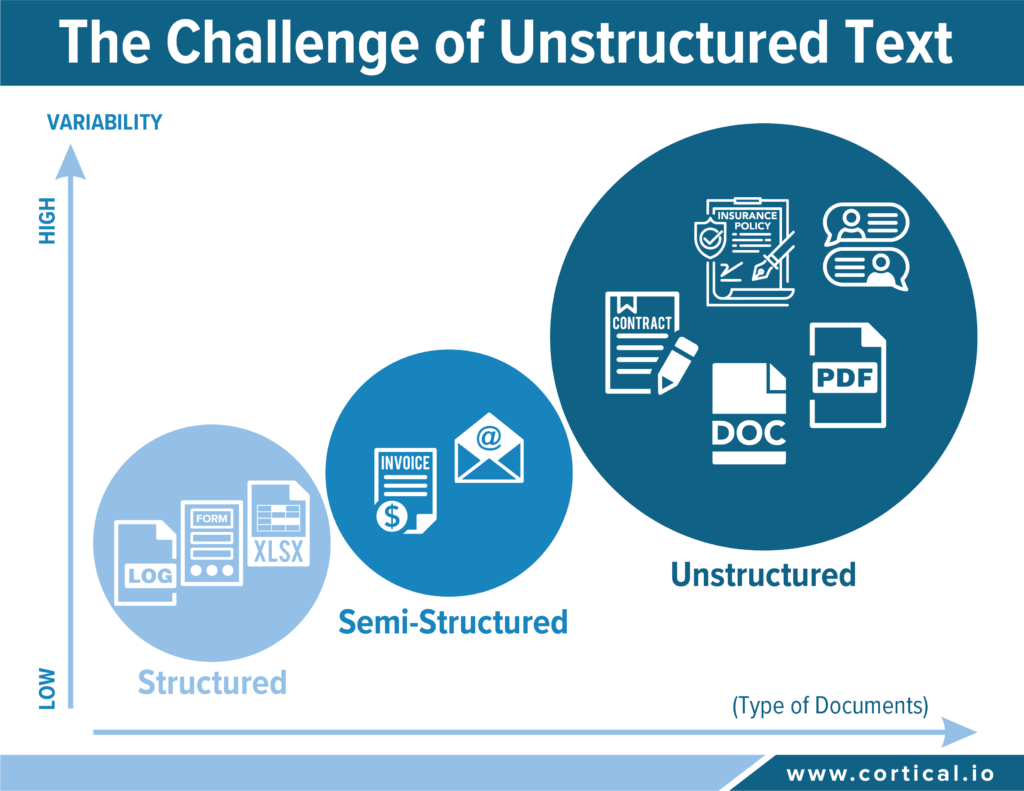
Some business documents processed by a company contain well-defined fields organized in rows and columns that can be easily analyzed and searched because they match with a pre-defined model. These so-called structured data account for less than 20% of all data produced: sales statistics, demographic information, financial reports, log data are typical examples of structured data.
Unstructured data is in direct correlation with the variability of the content
Unstructured data does not follow any pre-defined or known structure. Typically, unstructured information contains a lot of text, but might also include charts and graphics – contracts, insurance policies, PowerPoint presentations, PDFs and social media posts are good examples. In unstructured documents, exception prevails. In other words, it is impossible to define rules that can possibly cover all potential variations of content, whether in format or formulation.
The IDP market is largely dominated by solutions for structured and semi-structured documents
Why most IDP vendors focus on structured and semi-structured data is obvious. This kind of organized, templated information is easy to feed into rule-based systems that are trained to extract pre-defined terms from pre-defined places. Such models fail at accurately analyzing unstructured documents because the percentage of similar content is not high enough to enable generalization.
To accurately process unstructured text, an IDP solution must solve the challenges of language variety and ambiguity
Processing unstructured documents like contracts, insurance policies or social media posts is still an emerging market due to the complexity of these documents and the inability of legacy systems to understand the subtleties of human language.
Cortical.io has developed a meaning-based semantic platform that enables a new breed of IDP solutions. These solutions efficiently and accurately process unstructured text, enabling new operational efficiencies in terms of time savings and increased responsiveness.
To learn more about the challenge of unstructured text, download your free copy of our white paper: Intelligent Document Processing – The Challenge of Unstructured Text.
