
Today, companies are overwhelmed with the flood of digital communications from email, messaging, Twitter and other sources. Reacting in a timely manner to masses of messages spilling through different communication channels has become a business challenge for organizations. And the current environment with resource constraints, social distancing and working from home compounds the problem. More and more companies look for automation solutions to replace a manual process which is both too costly and too slow.
AI-based Natural Language Understanding (NLU) solutions have the potential to deal with this flood of messages by understanding the content of the messages, automatically and accurately classifying them, and then taking appropriate action such as routing, tagging, or handing off the message to an application. However, the sheer volume of messages represents a real challenge to the computing capacities of most existing solutions which, in addition, lack the accuracy of human workers to understand the meaning of ambiguous messages.
This is where Semantic Supercomputing comes into play. Semantic Supercomputing combines Semantic Folding, the patented NLU method from Cortical.io based on neuroscience, with the performance of the Xilinx Alveo U50 Data Center Accelerator Card to enable the processing of streams of natural language content at massive scale in real time.
Semantic Folding is a procedure for encoding the semantics of natural language in a sparse distributed representation called a semantic fingerprint. By mimicking the way the human brain processes language, Semantic Folding provides a framework for analyzing unstructured data in a very efficient manner. While standard machine learning approaches involve building large-scale statistical models and are trained with massive amounts of training data at a high computational cost, Semantic Folding uses topological sparse vectors enabling high computing efficiency. Semantic Folding also requires orders-of-magnitude less training material to build a highly precise model – a big advantage in the many instances where sufficient amounts of training data are not readily available. With Semantic Folding, each word, sentence or text document is converted in a semantic fingerprint, a 2-dimensional sparse binary vector with 16,384 elements.

Semantic Folding-based NLU algorithms such as search, classify or extract are implemented as binary operations on semantic fingerprints. These algorithms, implemented in hardware, taking advantage of the parallelism possible with Alveo Data Center Acceleration Cards, can provide an order-of-magnitude performance increase over standard CPU implementation.
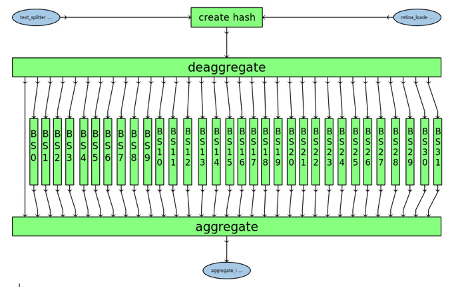
The Alveo Data Center Acceleration Card is a highly integrated heterogeneous compute unit capable of very complex tasks. In Message Intelligence, the first release of Cortical.io’s Semantic Supercomputing Appliance, this complexity is used to perform several tasks in a highly parallel manner which a regular CPU-based system cannot do. The system performs word-by-word lookup, by way of creating a hash for each word which is then matched against a database of semantic fingerprints of all words encountered in a large semantic space – e.g. Wikipedia. The system then uses Cortical.io’s unique algorithm to create a semantic meaning of an entire text, for example a message to be classified. This semantic meaning allows very efficient classification of the message, similar to how a human would “understand” the content of the text. In our example, the words in the database are divided into “frequent” (most frequently occurring in texts) and infrequent ones. The frequent terms are matched in extremely fast, massively parallel on-chip memory, the infrequent terms are indexed in parallel on a chip and retrieved from High-Bandwidth-Memory “HBM”. The diagram below shows the parallel indexing portion of the FPGA design, the massively parallel frequent term matching part is not shown as the number of parallel elements would exceed a useful graphic resolution.
Cortical.io Message Intelligence is the first of a series of Semantic Supercomputing appliances. Delivered in partnership with Xilinx, the solution can filter, classify, and route streams of messages in real time at a massive scale. It comes as a pre-packaged software and hardware solution with pre-built filters and classifiers that can be immediately applied to high volume message streams in an enterprise environment.
The vision for Semantic Supercomputing appliances is to make possible the broad implementation and deployment of AI solutions for automating business processes and solving the most challenging use cases that depend on human understanding, decision making, and execution.