
What is IDP?
The recent years have been characterized by digitalization efforts across all industries in order to transform business operations, automate key processes, gain operational efficiencies and improve customer experience. According to McKinsey Global Institute, 45% of all work activities in the United States could be automated immediately with existing technologies. The impact of such a digital transformation is huge. For example, BCG estimates that a full digital transformation can reduce operation costs by 20% to 40% over three to five years within the banking industry.
It is a fact that many organizational processes are still dominated by paperwork. Even if most documents are now digitized, the manual analysis of their content remains the rule – whether to monitor customer inquiries sent to a generic email address, compare locally-issued contracts to company templates, or extract key information from lease agreements to put on the balance sheet. On one hand, the sheer volume of documents makes it tedious and time-consuming to process manually. On the other hand, the complexity and disparity of content to review makes it difficult to automate these processes with state-of-the-art natural language processing techniques.
IDP Meaning: What does IDP stand for?
Intelligent Document Processing (IDP) is a method of automating data processing that combines Artificial Intelligence (AI) techniques, like machine learning and Natural Language Processing (NLP), with tools like Optical Character Recognition (OCR) to keep human intervention to a minimum. IDP vendors provide packaged solutions or platforms that capture data from a variety of sources, analyze it and then generate pre-defined actions such as classification into categories, extraction of key information, routing, and exporting the output to downstream applications. For any company dealing with large quantities of information, finding an effective intelligent document processing solution is a great opportunity to improve process efficiencies, reduce costs and increase margins.
However, the market for intelligent document processing is largely dominated by solutions offering capabilities to process structured and semi-structured documents like invoices, customer onboarding forms, or collaterals like IDs and passports. Processing unstructured documents like contracts, insurance policies or social media posts is still an emerging market because of the complexity of these documents and the difficulty for legacy systems to understand the subtilities of human language.
The challenge of automated data processing can be solved by a novel NLP approach inspired by neuroscience called Semantic Folding which enables a new breed of document automation solutions that efficiently and accurately process unstructured text, enabling new operational efficiencies in terms of time savings and increased responsiveness.
Intelligent Document Processing: The Challenge of Unstructured Data
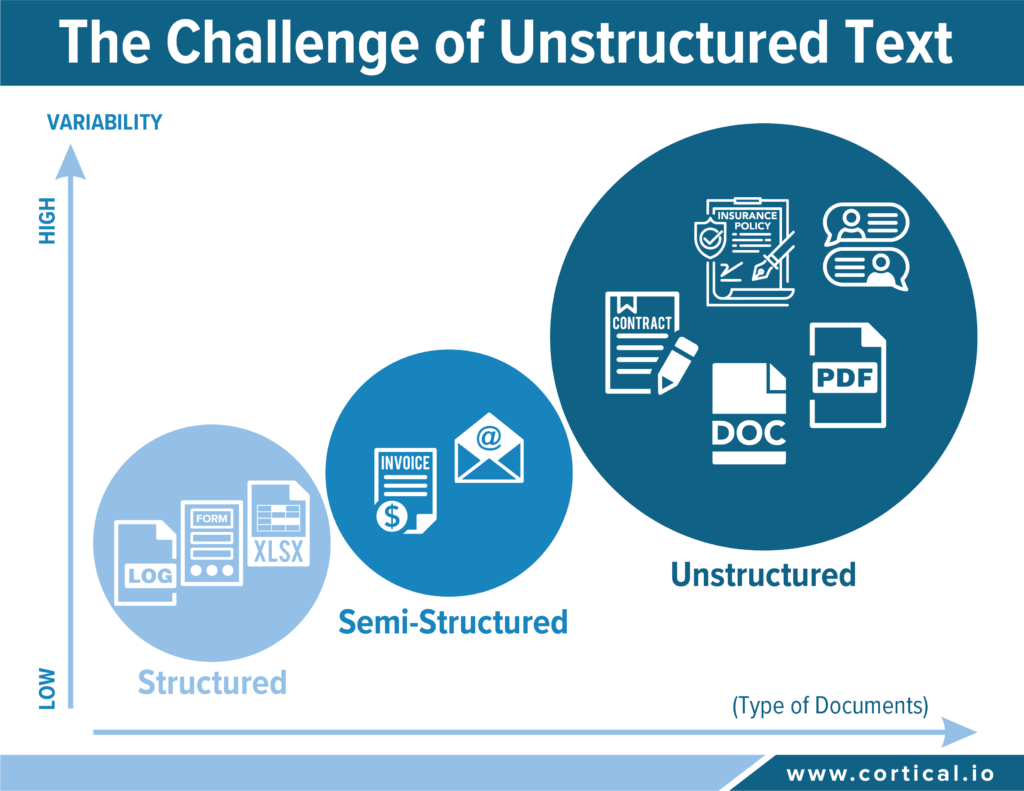
In order to better frame one’s expectations about document AI and intelligent document processing, it is essential to understand the difference between structured, semi-structured and unstructured data.
Some of the business documents processed by a company contain well-defined fields organized in rows and columns that are easily analyzed and searched through because they match with a pre-defined model. These so-called structured data account for less than 20% of all data produced: sales statistics, demographic information, financial reports, log data are typical examples of structured data. Rule-based systems and statistical systems are perfect to process this type of well-organized content.
The overwhelming part of documents, however, consists of unstructured data – 80% of the data produced worldwide is unstructured. This kind of data does not follow any pre-defined or known structure. Typically, unstructured information contains a lot of text, but might also include charts and graphics – contracts, insurance policies, PowerPoint presentations, PDFs and social media posts are good examples. In unstructured documents, exception prevails. In other words, it is impossible to define rules that can possibly cover all potential variations of content, whether in format or formulation. Statistical models also fail at accurately analyzing unstructured documents because the percentage of similar content is not high enough to enable generalization.
Semi-structured data exists in between structured and unstructured data. While they do not follow a formal structure like forms and spreadsheets, they do contain tags and other markers that enable to easily identify fields and establish hierarchies – a typical example an invoice with pre-defined fields and one or more line items.
Although the differences between structured, semi-structured, and structured text might sound very technical, it is vital to understand them to set accurate expectations and assess the capabilities of IDP software.
The Limits of Document Automation
The most common use cases for IDP software can be found in accounting (processing of invoices, purchase orders and receipts), human resources (employee onboarding), financial services (processing of checks and loan applications) and administration (processing forms and collaterals like driver licenses and passports). The majority of these use cases relies on state-of-the-art OCR, machine learning and NLP capabilities to capture and extract simple information (name, date, address, VAT-Number, etc.) for further processing by downstream applications like ERP and CRM systems.
Why most IDP systems focus on structured and semi-structured data is obvious: this kind of organized, templated information is easy to feed into rule-based systems that are trained to extract pre-defined terms from pre-defined places. Some IDP software vendors address the challenge of semi-structured and unstructured text data by offering out-of-the-box solutions for very specific use cases, like contract processing or lease abstraction. They come mostly from the document capture industry and have leveraged the hundreds of thousands or even millions of documents in their database to train their systems. This has little to do with intelligent document processing, as these systems are not capable of processing documents that do not match a template in their repository.
Such IDP systems can be implemented with little to no training and deliver highly accurate results, provided the documents to process and the company requirements exactly match the system parameters. But whenever the documents used by a company differ from the templates, or the user needs go beyond simple terms extractions, those system will fail to deliver accurate results.
Here are the two main reasons why IDP software vendors struggle to offer automated data processing solutions capable of generalizing the processing of unstructured text beyond very specific use cases:
1. The challenge of language variety
Corporate wording, product names, different ways of describing the same services, abbreviations, technical terminology, different vocabulary used by customers versus employees, etc.: the range of terms used within an organization is too broad to be captured as a whole, all the more as it evolves over time. The most advanced term-based NLP tools are not capable of processing terms they have not seen during training. Even if they have been trained with hundreds of billions of parameters, the training sets can’t possibly cover the complete spectrum of vocabulary used in a business context. In production, they perform poorly because they essentially ignore new terms. To improve their performance, these models would need to be trained with use-case specific data, which is all too often a scarce resource in the enterprise.
2. The challenge of language ambiguity
Human language is ambiguous, meaning the same word can have different meanings depending on its context. If I write “I see an apple on the desk”, do I mean apple the fruits, or apple the computer? We humans can infer the meaning of this sentence by the additional context we get, either visually or verbally. It is the same for computer systems: they need to be fed with additional context to be able to disambiguate such a sentence. But all too often, understanding the context means being able to interpret it, an intelligent task per se that would require document automation tools to understand high-level conceptual ideas, not only word statistics. This is why correctly interpreting ambiguous text remains one of the main impediments to automated data processing.
How Semantic Folding Supercharges Automated Data Processing
Semantic Folding builds upon a novel data representation called a semantic fingerprint that presents several advantages compared to other natural language processing (NLP) approaches. When text is converted in semantic fingerprints, all senses and contexts are preserved – even for sentences or whole business documents. This enables a fine-grained disambiguation of language and makes it possible to identify different formulations of the same concept. Such a meaning-based approach powers a document AI that can interpret complex clauses in contracts or insurance policies like a human, creating the opportunity to transform human labor-intensive workflows in the enterprise.
For example, group insurers need to review several complex documents like prior policies and benefit booklets of competitors to prepare a quote for a company. The larger insurers employ between 50 and 100 persons to perform this job manually because they do not trust automation tools. Traditional IDP systems miss important information because they fail at accurately understanding the meaning of certain formulations, for example recognizing that “Funding Method” and “Cost of Coverage” have the same meaning. However, an IDP software like Cortical.io SemanticPro that leverages a natural language understanding method like Semantic Folding can recognize different word formulations and automatically infer the correct contextual meaning. This results in an exceptional accuracy with unstructured data and enables to successfully automate a traditionally human-review intensive, error-prone workflow. Such an intelligent document automation not only reduces review cycle times, it also improves the quality of the quoting process.

Automatic Data Processing for Emails
Accurately analyzing high volumes of emails with attachments is another typical challenge for IDP systems where Cortical.io meaning-based approach makes a big difference in document automation. As an example, transportation companies receive every day an overwhelming amount of requests per email (between 100,000 and 250,000 customer emails daily), only 50% of which actually require a response. Their customer centers spend a significant amount of time sorting out emails that do not require action (e.g. out of office messages, FYI mails, etc.), from the business relevant ones. This task is further complicated by the fact that the emails are written in multiple languages. Understanding the meaning of short, highly variable texts (which emails often are) and accurately extracting key information from the attachments is a big challenge for most IDP systems. Not so for a meaning-based document automation solution leveraging Semantic Folding like Cortical.io SemanticPro: this IDP software can filter out and flag urgent emails, and route them to the appropriate departments in real time, thus dramatically improving response time and customer satisfaction.
Interestingly, only a small training data set (in the order of 100s) is required to reach a high level of accuracy with Semantic Folding – Compare this to the many thousands annotated documents required to fine-tune other natural language processing models used in most intelligent automation software. This opens a new range of use cases for workflow automation and business process optimization in the enterprise, in all business areas where too little training data exist to train conventional automated data processing software – for example, fraud detection in emails, scouting new talents within an organization, or monitoring social media posts for pharmacovigilance purposes.
Document Artificial Intelligence For Business Users
Another specificity of Cortical.io natural language understanding method is that it enables business users to train the SemanticPro AI, without requiring the intervention of machine learning specialists or data scientists. As a result, organizations can easily customize and quickly implement an IDP system that exactly matches their requirements, while achieving unmatched levels of accuracy when processing documents of unstructured nature. In terms of business value, this means that enterprises achieve their ROI faster through shorter deployment times and less human resources involved in training the IDP system.
Getting curious about how to speed up your digital transformation journey with Semantic Folding? Do you want to see how an intelligent automated data processing system like Cortical.io SemanticPro works? Fill in the contact form here or schedule a demo with our sales team here.